Neko: A Modern, Portable and Scalable Framework for High-Fidelity CFD
Niclas Jansson, PDC; Martin Karp, Jacob Wahlgren & Stefano Markidis, Division of Computational Science and Technology, KTH; Daniele Massaro & Philipp Schlatter, Department of Engineering Mechanics, KTH
With exascale computing capabilities on the horizon, the arena of computational research is transitioning to using systems with heterogeneous architectures. Traditional homogeneous scalar processing machines are being replaced with heterogeneous machines that combine scalar processors with various accelerators, such as graphics processing units (GPUs). Although these new systems offer high theoretical peak performance and high memory bandwidth, complex programming models and significant programming investments are necessary to make efficient use of the enhanced capability of such systems. Furthermore, most of the pre-exascale and exascale systems that are currently planned or that have already been installed (such as Frontier, the HPE Cray EX system at the US Department of Energy, and the LUMI system in Finland) contain a substantial number of accelerators. Thus, the challenges involved in porting scientific codes to these new platforms and tuning codes for these systems can no longer be ignored.
Computational Fluid Dynamics (CFD) is a natural driver for exascale computing as there is a virtually unbounded need for computational resources for accurate simulation of turbulent fluid flow, both for academic and engineering usage. However, established CFD codes build on years of verification and validation of their underlying numerical methods, potentially preventing a complete rewrite of a code base and rendering disruptive code changes a delicate task. Therefore, porting established codes to accelerators poses several interdisciplinary challenges, from formulating suitable numerical methods and performing hardware-specific tuning to applying sound software engineering practices to cope with disruptive code changes.
To address these challenges and to make it possible to perform high-fidelity fluid simulations on accelerated systems like LUMI and the second phase of Dardel, we have developed Neko, a portable framework for high-order spectral element-based simulations, mainly focusing on incompressible flow simulations. The framework is implemented in the contemporary 2008 version of Fortran and adopts a modern object-oriented approach allowing for multi-tier abstractions of the solver stack and facilitating various hardware backends. Using Fortran as the language of choice instead of languages that have been more popular recently, such as C++ or Python, might at first seem like an odd choice, particularly for developing a new code. However, Neko has its roots in the spectral element code Nek5000 (from the Argonne National Laboratory at the University of Chicago), which was introduced in the mid-nineties and traces its origins to the Massachusetts Institute of Technology’s even older NEKTON 2.0. Furthermore, research groups at the KTH Royal Institute of Technology (KTH) have extensively used the scalable Nek5000 code and also further developed its Fortran 77 codebase, thus creating a significant legacy of more than thirty years of verified and validated Fortran code, which, if rewritten in, for example, C++ would have to go through a very expensive and time-consuming revalidation and reverification process before it could be used in production. Therefore, by using modern Fortran, the already validated Fortran 77 kernels can be directly integrated into Neko, with only a minimal revalidation process.
Neko solves the incompressible Navier-Stokes equations, ensuring efficiency when running on systems with single-cores or accelerators via fast tensor product operator evaluations. For high-order methods, assembling either the local element matrix or the full stiffness matrix is prohibitively expensive. Therefore, a key to achieving good performance in spectral element methods is to consider a matrix-free formulation, where one always works with the unassembled matrix on a per-element basis. Gather–scatter operations ensure the continuity of functions on the element level, operating on both intra-node and inter-node element data. Currently, Neko uses MPI for inter-node parallelism and parallel I/O for production runs, but one-sided communication options (such as gather-scatter kernels based on Coarray Fortran) are under development.
When designing a flexible and maintainable framework for computational science, a major issue is finding the right level of abstraction. Too many levels might degrade performance, while too few results in a code base with many specialised kernels at a high maintenance cost. The weak form of the equation used in the Spectral Element Method allows Neko to recast equations in the form of the abstract problem to keep the abstractions at the top level and reduce the amount of platform-dependent kernels to a minimum. In Neko, this is realised using abstract Fortran types, with deferred implementations of required procedures. For example, to allow for different formulations of a simulation’s governing equations, Neko provides an abstract type, defining the abstract problem’s matrix-vector product. The type comes with a deferred procedure “compute” that would return the action of multiplying the stiffness matrix of a given equation with a vector. In a typical object-oriented fashion, whenever a routine needs a matrix-vector product, it is always expressed as a call to “compute” on the abstract base type and never on the actual concrete implementation. Abstract types are all defined at the top level in the solver stack during initialisation and represent large, compute-intensive kernels, thus reducing overhead costs associated with the abstraction layer. Furthermore, this abstraction also accommodates the possibility of providing tuned matrix-vector products for specific hardware, by only providing a particular implementation of “compute” without having to modify the entire solver stack.
Despite the abstraction, modern Fortran does not provide any easy answers on how to interface with accelerators. Although vendor-specific solutions (such as CUDA Fortran) or directives-based approaches are a popular choice when porting Fortran codes to accelerators, a decision was taken not to rely on these due to portability issues and reduced performance. Instead, Neko uses a device abstraction layer to manage device memory, data transfer and kernel launches from Fortran. Behind this interface, Neko calls the native accelerator implementation written in, for example, CUDA, HIP or OpenCL. Furthermore, if device-aware MPI is present, it is also exploited to minimise the necessary data movement between the host and device in communication kernels.
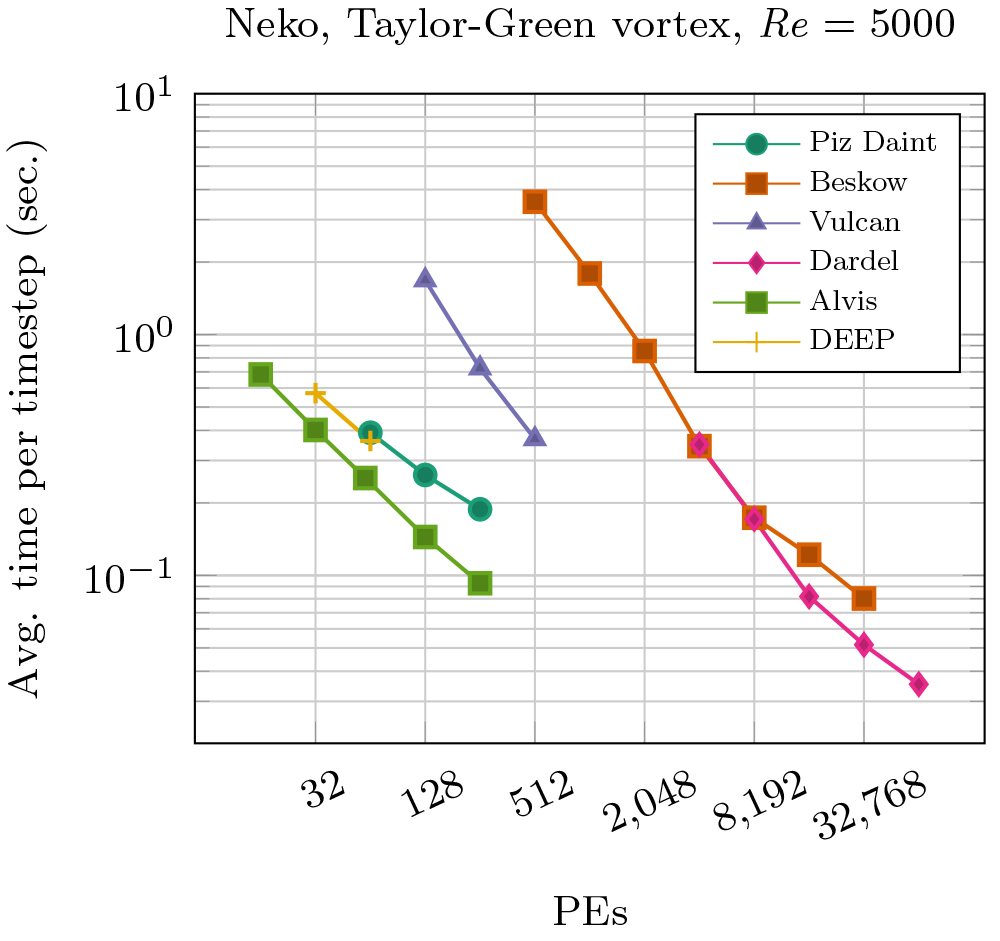
The ease of supporting various hardware backends through the solver stack and device layer abstraction is the key feature behind the performance portability of Neko, as illustrated in the graph below, where the time per time-step for solving the Taylor-Green vortex problem in various architectures is compared. Regardless of the architecture, Neko performs well on traditional general-purpose processors, SX-Aurora vector processors and various generations of accelerators.
Neko is currently used for large-scale direct numerical simulations (DNS) with applications in sustainable transport, studying the flow of air around Flettner rotors and the interaction of the flow with turbulent boundary layers. (A Flettner rotor is a rotating cylinder that will spin around its long axis as air passes across it. They were invented as rotor sails for ships about a hundred years ago and are now being studied as a clean and efficient method of propulsion to save fossil fuels.) A snapshot of these simulations is shown below. Thanks to PDC, Neko has already been ported and tuned for the new AMD MI250X accelerators in Dardel and LUMI; thus, the Neko developers are looking forward to exploiting these powerful systems once they become available to perform direct numerical simulations using previously untenable Reynolds numbers.

Neko is available as open source on GitHub ( github.com/ExtremeFLOW/neko ) and is distributed as part of the package manager Spack as “neko”.