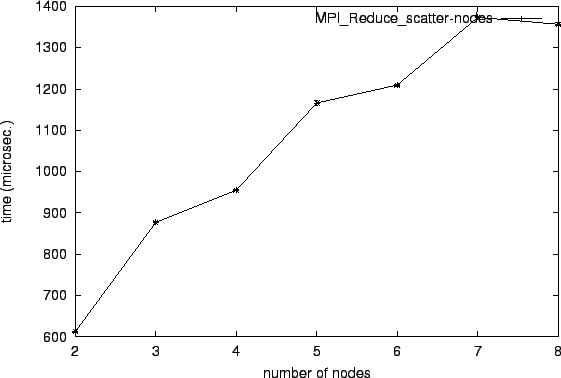
This operation performs a tree-wise data reduction operation (here:
bit-wise or) on all participating processes with MPI_Reduce_scatter and then distributes the result partially to
all participating nodes. Every node recieves a different part of the
result-array. This kind of result distribution to all paricipating
nodes is the difference to the normal MPI_Reduce or MPI_Allreduce operation, where the result is stored in a single
root processor resp. is transferred completely to all nodes. So it is
interesting to compare this operation to MPI_Allreduce, which
distributes the result to all nodes in one call. MPI_Reduce_scatter can also be compared with MPI_Reduce
followed by MPI_Scatterv, which we measure as MPI_Reduce_Scatterv. We vary over the number of nodes with a
message length of 256 Bytes for each node.
Pattern: Collective varied over number of nodes.
default values: 8 nodes, message length 256 units, max. / act. time for suite disabled/0.02 min.