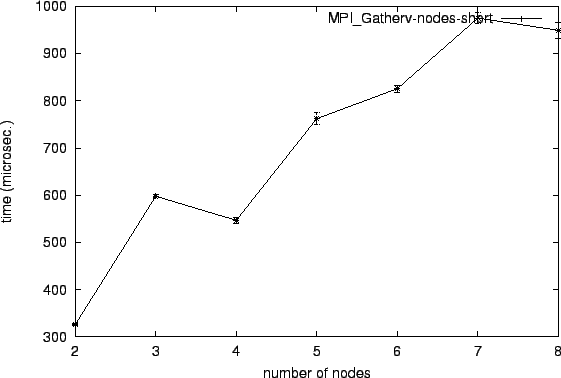
In the MPI_Gatherv operation a root process collects data from
every node and concats the received data in one buffer. In additon to
the MPI_Gather operation, we can use per processor receiving from a
specific displacement and length, which determine where to write
received data in the root's buffer and how man bytes to receive from
any processor. Of course, it is interesting to see, what are the extra
costs of this features. We vary over the number of nodes. The messages
have the length of 256 Bytes (for each node).
Pattern: Collective varied over number of nodes.
default values: 8 nodes, message length 256 units, max. / act. time for suite disabled/0.00 min.